부동산 허위매물 분류 해커톤 (2) - EDA
이번 글은 Dacon 부동산 허위매물 분류 해커톤에서 제공받은 데이터를 기반으로 수행한 EDA에 대한 글입니다. 사용된 데이터는 부동산 매물관련 정보가 포함된 정보였고 이를 활용하여 허위매물을 분류하는 AI 알고리즘을 개발하는 것이 대회의 주제였습니다. 제공 받은 데이터의 컬럼은 ID, 매물확인방식, 보증금, 월세, 전용면적, 해당층, 총층, 방향, 방수, 욕실수, 주차가능여부, 총주차대수, 관리, 중개사무소, 제공플랫폼, 게재일 그리고 정답인 허위매물여부였습니다. 일단 지난 전기차 예측은 회귀의 문제였다면 이번에는 분류의 문제로서 0과 1만을 구분하는 Binary 방식입니다.
먼저, 데이터 분석 이전에 부동산 시장은 우리의 삶의 필수 요소인 의, 식, 주 중에서 '주'에 해당함으로서 우리의 일상과 굉장히 밀접하게 연결되어 있습니다. 이 과정에서 부동산 거래를 통해 우리는 매물을 알아보게 되는 데, 여기서 허위매물은 신뢰가 기반이 되어야하는 부동산 거래에서 정말 중요한 문제입니다. 여기서 허위 매물이란, 실제 존재하지 않는 가상의 매물이거나 이미 거래된 예전 매물을 노출시키며 손님을 끄는 낚시용 매물이라고 정의할 수 있고 주어진 데이터를 기준으로 컬럼 중 하나라도 거짓이라면 그 부동산 매물은 허위매물이 됩니다. 따라서 허위매물을 효과적으로 탐지하고 제거 기술의 중요성은 부동산 시장의 투명성을 높이고 신뢰 기반의 부동산 거래 환경을 제공하는 데 기여할 수 있습니다.
그러면 이제, 제가 어떤 방식으로 EDA를 수행했고 데이터를 통해서 어떤 인사이트를 얻게 되었는 지 확인해보도록 하겠습니다.
데이터 링크 : https://dacon.io/competitions/official/236439/data
부동산 허위매물 분류 해커톤: 가짜를 색출하라! - DACON
분석시각화 대회 코드 공유 게시물은 내용 확인 후 좋아요(투표) 가능합니다.
dacon.io
탐색적 데이터 분석 (Exploratory Data Anaysis, EDA)
이번 대회에서 저는 아래와 같은 과정을 거치면서 EDA를 수행하였습니다. 물론 수 많은 시도(?)가 있었지만, 그 중에서 이번 대회에 결정적이었다고 생각했던 부분들만 살펴보도록 하겠습니다.
* EDA 과정
1. 컬럼 확인
2. 정답의 비율 확인
3. 이상치 확인
4. Describe
5. 분포도 확인
6. 데이터 변환
7. 정규화 시도
1. 컬럼 확인
일단 Data Load 이후에는 head와 tail을 통해서 데이터의 컬럼 혹은 특징(Feature)과 어떤 값을 가지고 있는 지 간략하게 살펴봅니다.
train.head(10)
train.tail(10)
여기서 head(10)는 위에서 0~9까지 10개 행을 보여주고, tail은 아래서 10개 행을 확인할 수 있습니다. 이것을 대략적으로 보면서 데이터를 어떻게 처리해야될 지 대강 예상을 하면서 다음을 준비해봅니다. 일단 저 같은 경우는 간략한 데이터를 보면서 보증금과 월세는 단위를 줄여야겠고, 방향, 주차가능여부, 제공플랫폼, 중개사무소는 범주화하야겠고 게재일 같은 경우는 년, 월, 일로 컬럼을 분리해야겠다는 생각을 하였습니다. 이후에는 train.colums를 통해서 컬럼 명을 따로 확인을 해둡니다.
train.columns
2. 정답의 비율 확인
이후 컬럼을 확인했다면 다음으로는 허위매물여부의 요소가 Binary인지 Multinominal 인지 확인하고 각각이 차지하는 비율을 확인하기 위해 아래와 같은 그래프를 그려서 데이터의 개수, 비율 그리고 시각화를 시도해봅니다.
# 허위매물여부 비율 계산
counts = train['허위매물여부'].value_counts()
percentages = counts / counts.sum() * 100 # 비율 계산
# 바차트 생성
plt.figure(figsize=(8, 6))
bar_plot = sns.barplot(x=counts.index, y=counts.values, palette='pastel')
plt.title('Distribution of 허위매물여부')
plt.xlabel('허위매물여부 (0: False, 1: True)')
plt.ylabel('Count')
plt.xticks(ticks=[0, 1], labels=['0 (허위매물 아님)', '1 (허위매물)'])
# 개수와 비율을 바차트 위에 추가
for p in bar_plot.patches:
bar_plot.annotate(f'{int(p.get_height())} ({p.get_height() / counts.sum() * 100:.1f}%)',
(p.get_x() + p.get_width() / 2., p.get_height()),
ha='center', va='bottom', fontsize=10)
plt.tight_layout()
plt.show()
3. 이상치 확인
이제 비율을 확인했다면 결측치를 확인해봅니다. 여기서 결측치란 알려지지 않고 수집되지 않거나 잘못 입력된 데이터 값을 의미합니다. 코드에서는 train.isnull().sum()을 통해서 결측치를 아래와 같이 확인할 수 있습니다.
train.isnull().sum()
코드를 통해 결측치가 있는 컬럼과 그 개수를 확인할 수 있습니다. 여기서 보면 전용면적, 해당층, 방수, 욕실수, 총주차대수의 컬럼이 결측치가 존재합니다. 이런 결측치를 보면서 저 같은 경우는 크게 아래와 같이 6가지 시도를 해봅니다. 이 중에서 5번 결측치가 있는 행을 제거하게 되면 대량의 데이터 정보가 날아가는 문제가 발생할 수 있기 때문에 이 방법을 시도해도 데이터 개수에 큰 영향을 미치지 않는 다면 한 번 시도해보시는 것을 추천드립니다.
* 결측치 처리 방법
1) 결측치를 전체 평균으로 결측치를 채운다.
2) 특정 컬럼을 기준으로 그룹화한 다음에 그룹별로 평균을 채운다.
3) 최댓 값, 최솟 값, 최빈값, 0을 채운다.
4) 결측치가 있는 컬럼을 제거한다.
5) 결측치가 있는 행을 제거한다. (비 추천)
6) 그냥 쓴다.
* 주의 사항 : test에도 같은 방법을 적용해야된다.
4. Information & Describe
결측치까지 확인을 했다면 이제 수치적으로 대략적인 정보를 확인해봅니다. 물론 범주형 변수도 있기 때문에 이를 train.info()와 train.describe()를 통해서 컬럼의 Dtype이 무엇인지 그리고 개수, 평균, 편차, 최대, 최소 등을 확인을 해봅니다.
train.info()
train.describe()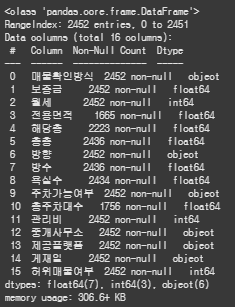
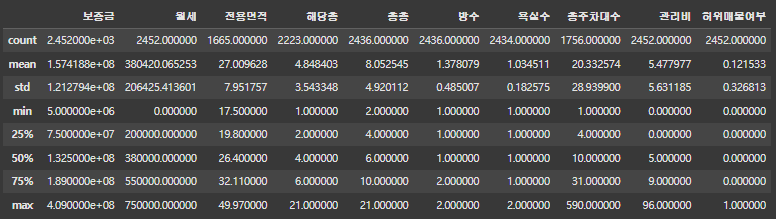
여기서 describe를 간과하시는 분들이 많은 데, 여기서도 충분한 정보를 획득 할 수 있습니다. 평균을 기준으로 최대, 최도가 얼만큼 떨어져 있는 지 그리고 중간 값을 기준으로 평균이 왼쪽에 있나 오른쪽에 있나를 보고 데이터의 왜도(치우친 정도) 등을 확인할 수 있습니다. 또한 편차를 통해서 평균과 비교하여 얼마나 떨어져있는지 값을 확인할 수 있습니다. 보통 데이터 분석을 할 때, 통계적 지식이 아예 없으신 상태에서 분석을 시도하면 보통 감으로 하시는 분들이 많기 때문에 ADsP, 빅데이터 분석 기사를 통해 자격증도 취득하면서 대략적인 통계지식도 얻으시는 것을 추천드립니다.
5. 분포도 확인
이제 전반적인 데이터의 분포, 개수, 이상치를 확인해봅니다. 이때, 히스토그램 혹은 Bar 그래프 박스 플롯 등을 사용할 수 있고 저는 여기서 히스토그램을 사용해서 그래프를 확인해보았습니다.
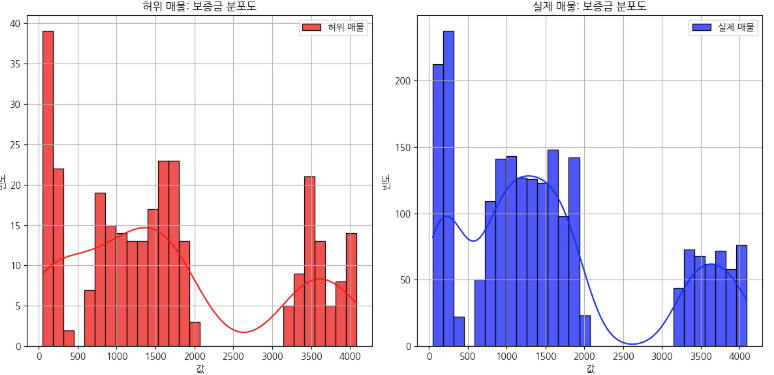
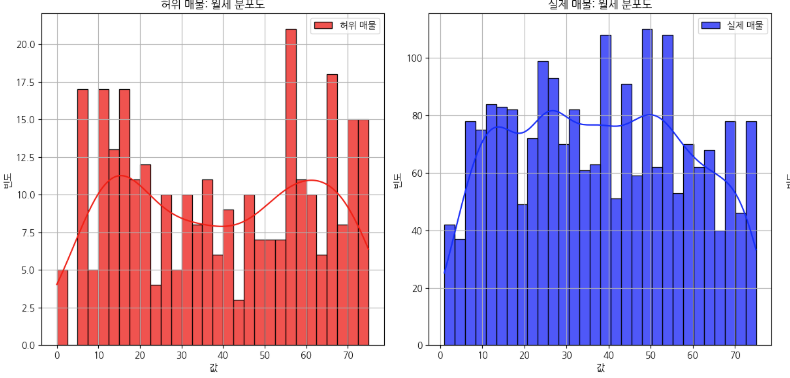
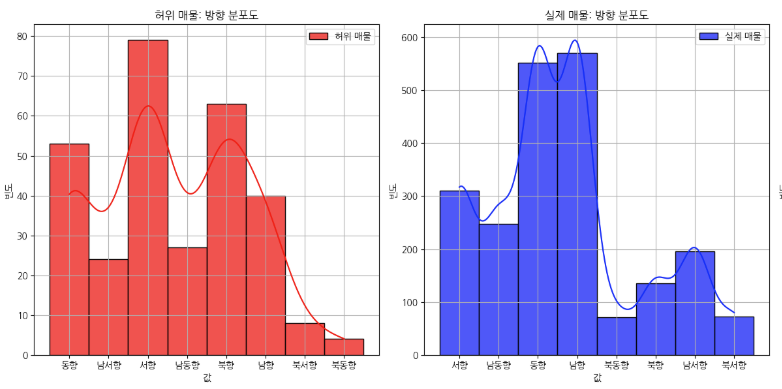
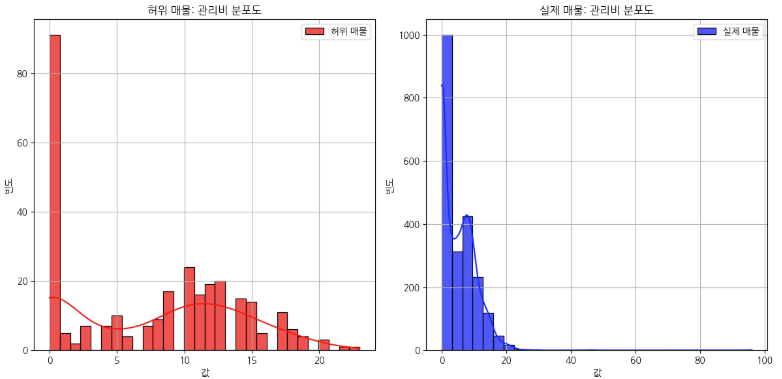
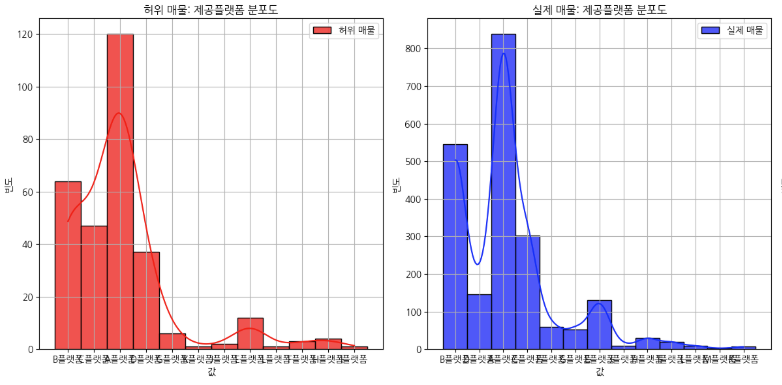
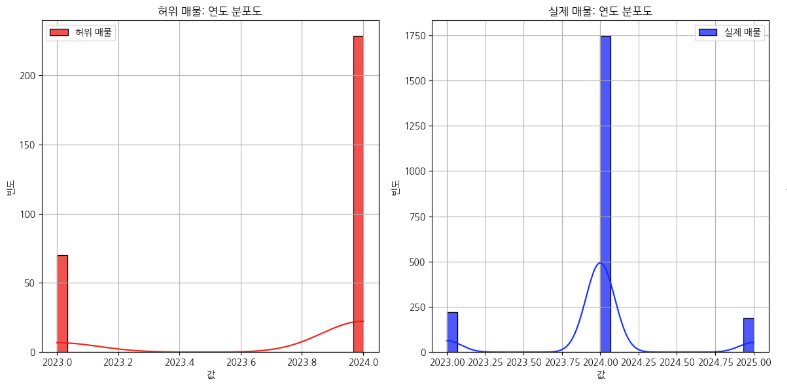
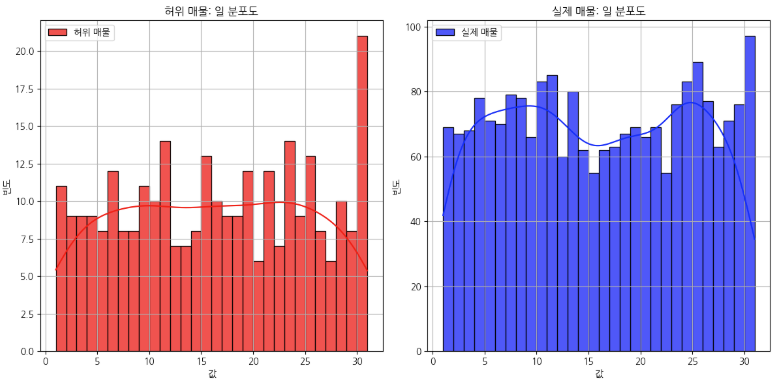
일단 이런식으로 그래프를 쭉 확인하면서 저는 왼쪽에는 가짜매물(1), 실제매물(0)을 기준으로 비교하는 방식으로 그래프를 주로 보고 있습니다. 어짜피 1과 0을 비교한다면 Trade-Off 문제가 발생하게 되기 때문에 각각 그래프로 비교하면서 어떤 1을 가지고 있는 컬럼들과 0을 가지고 있는 컬럼들의 특징을 확인해봅니다. 그래프의 모양을 보면서 분포도가 오른쪽에 치우쳐져 있다면 왼쪽 끝에는 분명히 이상치가 있을 테고, 왼쪽으로 치우쳐져 있다면 오른쪽 끝에 이상치가 있다는 것을 알 수 있습니다. 보통 그래프를 보면 고루 분포되어 있구나 라고 넘어갈 수 있습니다. 다만 제가 대회에서 예외적인 것을 발견했던 '월' 그래프를 살펴보도록 하겠습니다.
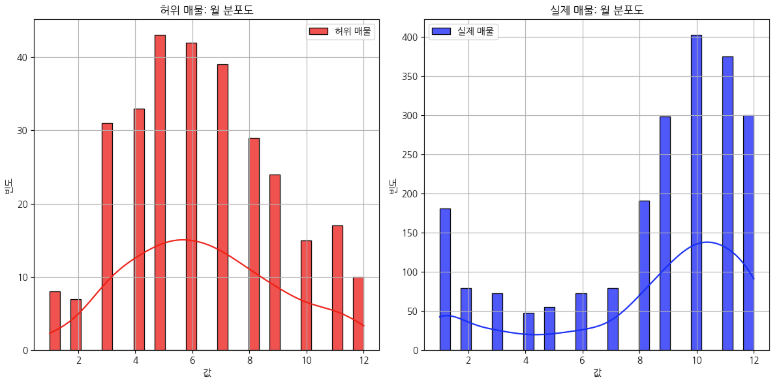
해당 그래프를 보시면 허위 매물은 1월부터 12월까지 정규분포의 모양을 띄고 있고, 왼쪽 그래프는 다른 것을 확인할 수 있습니다. 이 과정에서 저는 8, 9, 10, 11, 12월의 데이터에 뭔가 있다는 것을 일단 기억을 해두고 계속해서 기본 작업을 수행해봅니다.
6. 데이터 변환
다음은 컬럼 요소 중 범주형 변수에 대한 인코딩을 수행합니다. 간략하게 말씀드리면 범주형을 숫자로 바꾼다는 말입니다. 다만 이번 대회의 데이터는 컬럼 중에서 중개사무소 컬럼이 train과 test에 있는 것과 없는 것들이 있기 때문에 이를 충분히 고려해서 인코딩을 진행해야합니다. 보통 인코딩 작업을 수행하는 의 경우는 get_dummies와 LabelEncoder를 사용하게 되는 데, get_dummies 같은 경우를 사용하게 된다면 컬럼이 무수하게 많아지는 문제가 발생하기 때문에 범주가 많지 않다면 get_dummies를 사용하시고 범주가 많다면 LabelEncoder를 사용하시는 것을 추천드립니다.
# LabelEncoder 인스턴스 생성
label_encoders = {}
label_encode_cols = train.select_dtypes(include=['object']).columns.difference(['ID']).tolist()
# train 데이터프레임의 각 object 타입 컬럼에 대해 LabelEncoder 적용 (ID 제외)
for col in label_encode_cols:
le = LabelEncoder()
train[col] = le.fit_transform(train[col])
label_encoders[col] = le # LabelEncoder 저장
# test 데이터프레임의 각 object 타입 컬럼에 대해 LabelEncoder 적용 (ID 제외)
for col in label_encode_cols:
if col in test.columns:
le = label_encoders[col]
test[col] = test[col].astype(str) # 데이터 타입을 문자열로 변환
unseen = set(test[col].unique()) - set(le.classes_) # 보지 못한 값 확인
# 보지 못한 클래스 추가
if unseen:
le.classes_ = np.append(le.classes_, list(unseen)) # 새로운 클래스 추가
# 변환
test[col] = le.transform(test[col])
7. 정규화
이제 학습 직전인 데이터 정규화만 남았습니다. 여기서 정규화를 간단하게 말씀드리자면 보통 정규화의 경우에는 MinMax 스케일러, Standard 스케일러를 사용하게 되는 데, 이 밖에도 Robust, PowerTransformer 등이 있는 데, 대표적인 MinMax와 Standard로도 충분한 결과를 만들어내실 수 있습니다. 하지만 뭔가 새로운 도전을 하고 싶으시다면 데이터의 특징들을 잘 살펴보시고 상황에 맞는 스케일러를 탐색해서 사용해보시길 바라겠습니다.
from sklearn.preprocessing import StandardScaler
# StandardScaler 인스턴스 생성
scaler = StandardScaler()
# StandardScaler를 사용하여 x_train과 x_test 정규화
x_train_scaled = scaler.fit_transform(x_train)
x_test_scaled = scaler.transform(x_test)
x_test_scaled
마무리
여기까지 제가 대회 중 수행했던 EDA를 7단계에 거쳐서 살펴보는 시간을 가졌습니다. 최근 대회를 하면서 ADsP를 같이 준비를 했었는 데, 이전에는 통계적 지식에 대해서 그렇게 중요하다고 생각하지 않았지만 ADsP를 보면서 간략하게나마 통계적인 지식을 데이터에 적용해보면서 이론을 절대 무시하면 안되겠다라는 교훈을 얻을 수 있었습니다. 이런 경험을 해보면서 통계에 대한 이론적인 것을 좀 더 공부를 해보아야겠다는 생각이 들었고, 제가 시도해보지 않은 다양한 시각화들 또한 배울 게 산더미 같이 많을 것 같습니다. 대회를 통해서 다양한 시도를 해보지만 언제나 늘 같은 실력 안에서 빙빙 돌고 있다는 생각이 들었는 데, ADsP를 통해서 조금이나마 많은 것을 배울 수 있었습니다. 그럼, 실제 대회에서 사용했던 내용들은 다음 글을 통해서 살펴보도록 하고 그럼 이번 글은 여기서 마치도록 하겠습니다.
'Personal Projects > Dacon' 카테고리의 다른 글
| [Dacon] 건설공사 사고 예방 및 대응책 생성 경진대회 (1) - 후기 (0) | 2025.03.24 |
|---|---|
| [Dacon] 부동한 허위매물 분류 해커톤 (3) - 최종 코드 (0) | 2025.02.28 |
| [Dacon] 부동산 허위매물 분류 해커톤 (1) - 후기 (Private 43, 상위 10%) (0) | 2025.02.28 |
| [Dacon] 전기차 가격 예측 해커톤 (3) - Prediction Process (0) | 2025.01.31 |
| [Dacon] 전기차 가격 예측 해커톤 (2) - EDA (0) | 2025.01.31 |



