건설공사 사고 예방 및 대응책 생성 - Code
안녕하세요. 이번 글은 건설공사 사고 예방 및 대응책 생성 대회에서 제가 사용했던 RAG를 활용한 코드에 대해서 살펴보도록 하겠습니다. 비록 대회에서 큰 성적을 거두지는 못했지만, 처음으로 RAG를 공부하면서 알게된 것들 그리고 전반적으로 고민했던 것과 그것을 바탕으로 작성된 코드를 살펴보도록 하겠습니다. 일단 아래를 통해서 이번 글의 내용을 간략하게 살펴보겠습니다. (참고로 대회에서 사용된 데이터는 제가 함부로 제공할 수 없으니, 아래 데이콘 링크를 통해서 문의해주세요!)
* 코드 주요 내용
1. PDF & CSV Load
2. Text Splitter
3. Text Embedding
4. Vector Store
5. Retriever
6. Chain
7. Inference
데이콘 링크
: https://dacon.io/competitions/official/236455/overview/description
건설공사 사고 예방 및 대응책 생성 : 한솔데코 시즌3 AI 경진대회 - DACON
분석시각화 대회 코드 공유 게시물은 내용 확인 후 좋아요(투표) 가능합니다.
dacon.io
GitHub
: https://github.com/Muns91/RAG-Construction-Accident-Prevention-and-Response-Measures/tree/main
GitHub - Muns91/RAG-Construction-Accident-Prevention-and-Response-Measures
Contribute to Muns91/RAG-Construction-Accident-Prevention-and-Response-Measures development by creating an account on GitHub.
github.com
Code Review
■ 개발 환경 : RunPod
* RunPod를 모르신다면?
: 2025.02.25 - [Information/기타 정보] - [RunPod] 고성능 컴퓨팅 환경을 활용하고 싶다면? RunPod!
[RunPod] 고성능 컴퓨팅 환경을 활용하고 싶다면? RunPod!
런팟 (RunPod)란? 최근 LLM과 관련된 Dacon 프로젝트를 수행하게 되면서, 기존 제가 가지고 있는 컴퓨팅 환경은 그 성능에 한계가 있다는 큰 문제가 있었습니다. 물론 학교 컴퓨터를 교수님께 양
muns-da2.tistory.com
■ 컴퓨팅 리소스 :
- A40
- 48 GB VRAN
- 48 GB RAM, 9 vCPU
■ 사용 언어 : Python
0. Install & Library & Hyper Parameters
!pip install pypdf
!pip install -U langchain-community
!pip install sentence-transformers
!pip install -U bitsandbytes
!pip install PyPDF2
!pip install numpy==1.23.5
!pip install pandas
!pip install -U langchain-huggingface
!pip install accelerate>=0.26.0
!pip install fitz
!pip install frontend
!pip install pdfplumber
!pip install langchain PyPDFium2
!pip install faiss-gpu
!pip install grandalf
!pip install rank_bm25
!pip install tiktoken
!pip install -qU langchain-teddynote
!pip install matplotlib
!pip install chromadb
!pip install --upgrade langchain pydantic
!pip install pymupdf4llm
!pip install seaborn
import os
import re
import torch
import numpy as np
import pandas as pd
from tqdm import tqdm
from langchain.document_loaders import PyPDFium2Loader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.llms import HuggingFacePipeline
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline, BitsAndBytesConfig
from langchain.retrievers import BM25Retriever, EnsembleRetriever
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
from langchain_community.vectorstores import Chroma
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.chains import RetrievalQA
from langchain_community.llms import HuggingFacePipeline
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
from transformers import pipeline
from transformers import BitsAndBytesConfig, AutoTokenizer, AutoModelForCausalLM
from langchain.prompts import PromptTemplate
from sentence_transformers import SentenceTransformer
from langchain.retrievers.document_compressors import EmbeddingsFilter
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
import pymupdf4llm
from langchain.document_loaders import PyMuPDFLoader
from langchain_community.document_loaders import PDFMinerLoader
from langchain_community.document_loaders import UnstructuredPDFLoader
from langchain_community.document_loaders import PDFMinerPDFasHTMLLoader
from langchain_community.document_loaders import PDFPlumberLoader
from langchain.retrievers.document_compressors import DocumentCompressorPipeline
from langchain_community.document_transformers import EmbeddingsRedundantFilter
from langchain_teddynote.document_compressors import LLMChainExtractor
from langchain.retrievers import ContextualCompressionRetriever
import pdfplumber
import matplotlib.pyplot as plt
RAG_Embedding_model = "jhgan/ko-sbert-nli"
# BAAI/bge-m3
TEST_Embedding = "jhgan/ko-sbert-sts"
LLM_Model ="CarrotAI/Llama-3.2-Rabbit-Ko-3B-Instruct-2412"
# "beomi/OPEN-SOLAR-KO-10.7B"
# "yanolja/EEVE-Korean-Instruct-10.8B-v1.0"
model_kwargs = {'device': 'cuda'}
encode_kwargs = {'normalize_embeddings': True}
# Text splitter
N_Chunk_size = 1000
N_Chunk_overlab = 100
R_k = 3
# Ensemble Retirever
# 1. CSV
# 2. PDF
Ensemble_rate = [0.5, 0.5]
# Sample Test
Max_token_length = 100
# EmbeddingsFilter
# threshold = 0.8
1. Load PDF
def clean_text(text):
# 줄바꿈 제거
#text = text.replace("\n", " ")
# 'KOSHA GUIDE' 제거
text = text.replace("KOSHA GUIDE", "")
# 4자리 숫자(년도) 제거
text = re.sub(r"\b\d{4}\b", "", text)
# [참고'숫자'] 형태 제거
text = re.sub(r"\[참고'\d+'\]", "", text)
# '[글자]' 형태 제거
text = re.sub(r"'\w+'", "", text)
# '- 숫자 -' 형태 제거
text = re.sub(r"-\s*\d+\s*-", "", text)
# '<사진 숫자>' 형태 제거
text = re.sub(r"<(사진|그림|표)\s*\d+>|(사진|그림|표)\s*\d+", "", text)
# 불필요한 공백 정리
text = re.sub(r"\s+", " ", text).strip()
return text
def load_pdfs_from_folder(folder_path):
documents = []
pdf_files = [f for f in os.listdir(folder_path) if f.endswith(".pdf")]
# PDF 파일 로드 진행 상황 표시
for file_name in tqdm(pdf_files, desc="PDF 파일 로드 중", unit="파일"):
file_path = os.path.join(folder_path, file_name)
with pdfplumber.open(file_path) as pdf:
# 각 페이지 로드 진행 상황 표시
for i in tqdm(range(len(pdf.pages)), desc=f"{file_name} 페이지 로드 중", unit="페이지"):
page = pdf.pages[i]
# 표와 이미지를 제외하고 텍스트만 추출
text = page.extract_text()
if text:
# 전처리 적용
cleaned_text = clean_text(text)
if cleaned_text: # 전처리 후에도 텍스트가 남아있다면 추가
documents.append({
"page_content": cleaned_text,
"metadata": {
"source": file_path,
"page": i + 1
}
})
return documents
# PDF 문서 로드
pdf_docs = load_pdfs_from_folder("건설안전지침/")Page_num = 150
print(pdf_docs[Page_num])
일단, 먼저 대회에서 제공된 데이터는 104개의 안전지침과 관련된 PDF일과 CSV 파일로 이루어져 있습니다. 대회 규칙에 따라서 일단, 모든 데이터를 활용해야하는 데, 그를 위해서 먼저 PDF 파일을 위와 같이 불러왔고, 그 과정에서 사용된 PDF Loader는 "pdfplumber"가 사용되었습니다. 이를 통해서 저는 PDF의 내용 뿐만 아니라, PDF 파일 이름, Page 번호 등과 같은 메타파일을 얻을 수 있었습니다.
그리고 추가적으로 데이터를 그냥 Loader를 통해서 불러오면 그림과 표가 깨져서 나오는 데, 저는 건설 안전 지침에 대한 사항만 필요했기 때문에 이는 필요없어서 별도로 전처리를 통해 없애는 과정을 통해서 오로지 '문장'만 추출하는 과정을 거쳤습니다.
2. Text Splitter
def split_documents(documents, chunk_size=1000, chunk_overlap=100):
text_splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", " ", ""],
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
length_function=len,
is_separator_regex=False,
)
chunks = []
page_lengths = []
for doc in documents:
splits = text_splitter.split_text(doc["page_content"])
page_length = len(doc["page_content"])
page_lengths.append({
"source": doc["metadata"]["source"],
"page": doc["metadata"]["page"],
"page_length": page_length
})
for split in splits:
chunks.append({
"source": doc["metadata"]["source"],
"page_number": doc["metadata"]["page"],
"text": split
})
return chunks, page_lengths
# PDF 문서에서 텍스트 분할 및 페이지 길이 확인
pdf_chunks, page_lengths = split_documents(pdf_docs)pdf_chunks[45]
page_lengths_values = [p['page_length'] for p in page_lengths]
# 최대, 최소, 평균 길이 출력
max_length = max(page_lengths_values)
min_length = min(page_lengths_values)
avg_length = np.mean(page_lengths_values)
print(f"📏 최대 페이지 길이: {max_length}")
print(f"📏 최소 페이지 길이: {min_length}")
print(f"📏 평균 페이지 길이: {avg_length:.2f}")
다음은 Text Splitter입니다. 이 과정에서 저는 RecursiveCharacterTextSplitter를 사용해서 텍스트를 분할하는 과정을 거쳤습니다. 이 과정에서 chunk_size, chunk_overlap은 아래에 따른 통계에 따라서 평균이 587.25이니, 적당히 사이즈 1000과 오버랩 100으로 맞추는 작업을 수행하였습니다. 여기서 사이즈와 오버랩은 제 경우에는 사이즈에 변화에도 성능에는 큰 변화는 없었습니다.
3. Reduce Page
# page_lengths에서 인덱스와 page_length 추출
page_lengths_values_with_index = [(index, p['page_length']) for index, p in enumerate(page_lengths)]
# DataFrame 생성
df_page_lengths = pd.DataFrame(page_lengths_values_with_index, columns=["Index", "Page Length"])
# 결과 출력
df_page_lengths_filtered = df_page_lengths[df_page_lengths["Page Length"] <= 50]
# 결과 출력
df_page_lengths_filtered.head()# Define the bins with intervals of 100
bin_intervals = range(0, max_length + 100, 50)
# Plot the histogram with the new bin intervals
plt.figure(figsize=(10, 6))
plt.hist(page_lengths_values, bins=bin_intervals, color='skyblue', edgecolor='black')
# Add titles and labels
plt.title("Distribution of PDF Page Lengths")
plt.xlabel("Page Length (Number of Characters)")
plt.ylabel("Number of Pages")
plt.grid(axis='y', linestyle='--', alpha=0.7)
# Show the plot
plt.show()
# Print the counts for each bin
counts, bin_edges = np.histogram(page_lengths_values, bins=bin_intervals)
# Display the bin ranges and corresponding counts
for i in range(len(counts)):
print(f"Bin {bin_edges[i]} - {bin_edges[i+1]}: {counts[i]} pages")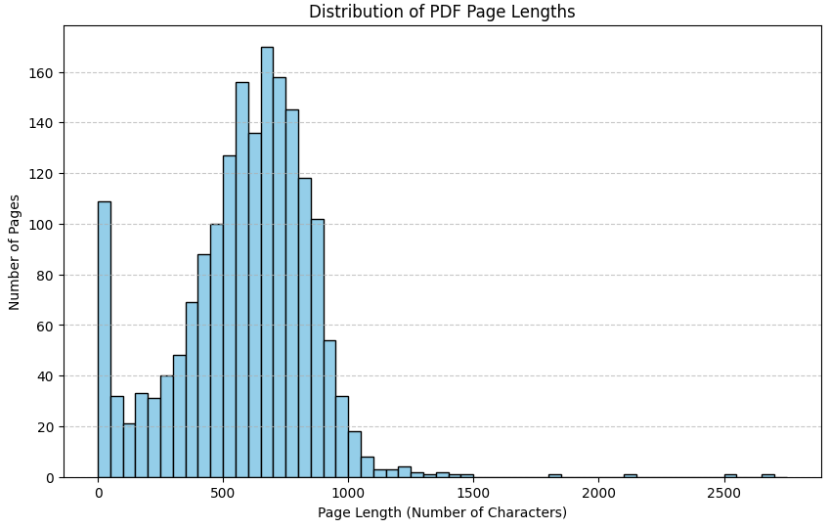
import seaborn as sns
# 'text'의 길이를 계산
text_lengths = [len(chunk['text']) for chunk in pdf_chunks]
# 분포도 그리기
plt.figure(figsize=(10, 6))
sns.histplot(text_lengths, bins=30, kde=True)
plt.title('PDF Chunks Text Length Distribution')
plt.xlabel('Text Length')
plt.ylabel('Frequency')
plt.grid(True)
plt.show()
# 0에서 1000 사이의 길이를 가진 요소의 수 확인
filtered_lengths = [length for length in text_lengths if 0 <= length <= 1000]
# 구간 설정
bin_intervals = range(0, 1050, 50)
# 각 구간의 개수 계산
counts, bin_edges = np.histogram(filtered_lengths, bins=bin_intervals)
# Bin 0 - 100에 해당하는 인덱스 찾기
bin_0_to_100_indices = [i for i, length in enumerate(filtered_lengths) if 0 <= length < 100]
# Bin 0 - 100에 해당하는 요소 제거
filtered_lengths = [length for i, length in enumerate(filtered_lengths) if i not in bin_0_to_100_indices]
# 제거 후 결과 출력
print("제거 후 filtered_lengths의 길이:", len(filtered_lengths))
# 제거 후 filtered_lengths의 길이: 1725
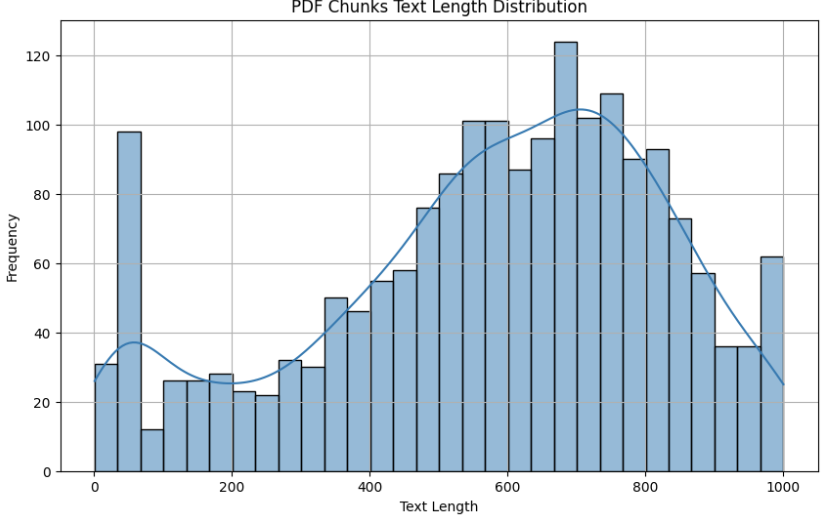
Text Splitter 이후에는 PDF 파일에서 첫 페이지와 같은 내용들은 불필요하다고 판단했기 때문에 이를 없애기 위해 Bin을 사용하여 히스토그램을 그려 페이지의 분포도를 살펴보았습니다. 그 과정에서 글자수가 너무 적은 곳의 리스트를 뽑아서 확인해보니, 대부분은 안전지침의 맨 앞 페이지 혹은 뒷페이지에 해당되는 부분이었습니다. 따라서 이는 유사성에 따라서 쓸모없는 부분이 추출될 가능성을 배제하기 위해서 전처리를 통해 해당 구간들은 모두 제거하였습니다.
4. CSV Load
# 5. 데이터 전처리 (Train & Test 데이터)
train = pd.read_csv('./train.csv', encoding='utf-8-sig')
test = pd.read_csv('./test.csv', encoding='utf-8-sig')
# 특정 컬럼 제거
columns_to_drop = ['발생일시', '사고인지 시간', '날씨', '기온', '습도', '연면적', '층 정보']
# train 데이터에서 컬럼 제거
train = train.drop(columns=columns_to_drop)
# test 데이터에서 컬럼 제거
test = test.drop(columns=columns_to_drop)
# 결측치 처리 (빈 문자열로 채우기)
train['공사종류'] = train['공사종류'].fillna('')
train['공종'] = train['공종'].fillna('')
train['사고객체'] = train['사고객체'].fillna('')
train['작업프로세스'] = train['작업프로세스'].fillna('')
train['사고원인'] = train['사고원인'].fillna('')
test['공사종류'] = test['공사종류'].fillna('')
test['공종'] = test['공종'].fillna('')
test['사고객체'] = test['사고객체'].fillna('')
# 데이터 전처리
train['공사종류(대분류)'] = train['공사종류'].str.split(' / ').str.get(0)
train['공사종류(중분류)'] = train['공사종류'].str.split(' / ').str.get(1)
train['공종(대분류)'] = train['공종'].str.split(' > ').str[0]
train['공종(중분류)'] = train['공종'].str.split(' > ').str[1]
train['사고객체(대분류)'] = train['사고객체'].str.split(' > ').str[0]
train['사고객체(중분류)'] = train['사고객체'].str.split(' > ').str[1]
test['공사종류(대분류)'] = test['공사종류'].str.split(' / ').str[0]
test['공사종류(중분류)'] = test['공사종류'].str.split(' / ').str[1]
test['공종(대분류)'] = test['공종'].str.split(' > ').str[0]
test['공종(중분류)'] = test['공종'].str.split(' > ').str[1]
test['사고객체(대분류)'] = test['사고객체'].str.split(' > ').str[0]
test['사고객체(중분류)'] = test['사고객체'].str.split(' > ').str[1]
# 훈련 데이터 통합 생성
combined_training_data = train.apply(
lambda row: {
"question": (
f"'{row['작업프로세스']}', '{row['인적사고']}', '{row['사고원인']}' "
),
"answer": row["재발방지대책 및 향후조치계획"]
},
axis=1
)
combined_training_data = pd.DataFrame(list(combined_training_data))
combined_training_data = pd.concat([train['ID'], combined_training_data], axis=1)
combined_training_data['Type'] = 'csv'
combined_training_data.head(5)
train_documents = [
f"Q: {q1}\nA: {a1}"
for q1, a1, in zip(combined_training_data['question'], combined_training_data['answer'])
]
train_documents[:5]
이번 작업에서는 대회에서 제공된 두 번째 파일인 'CSV' 파일에 대한 작업입니다. 해당 데이터는 PDF 파일과 같이 별도의 Text Splitter는 사용하지 않았습니다. 이후에는 train_documents를 통해서 Vector DB에 넣을 데이터를 구성하고 그 안에는 'question'과 'answer'가 들어가게 하였습니다. 나머지는 뒤에서 언급하겠지만, Vector DB에 Meta data로 들어가게 구성하였습니다.
5. Text Embedding
embedding_model_name = RAG_Embedding_model
embedding = HuggingFaceEmbeddings(
model_name=embedding_model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
이제 Vector DB로 데이터를 옮기기 전 Text Embedding 작업을 수행합니다. 여기서 주어진 텍스트 데이터를 임베딩 벡터로 변환할 준비를 하는 데, 이를 위해서 HuggingFaceEmbeddings를 사용했고, 임베딩을 위한 오픈소스 모델은 위의 Hyper Parameter에서의 RAG_Embedding_model = "jhgan/ko-sbert-nli" 이것을 사용하였습니다. 여기서 임베딩 모델 또한, 다양한 것을 사용해보았으나, 대회 순위에는 큰 영향을 미치지 않았습니다.
6. Vector DB
# 텍스트 추출
text_set = [chunk["text"] for chunk in pdf_chunks]
# 메타데이터 추출 (Type 추가)
metadata_set = [
{
"source": chunk["source"],
"page_number": chunk["page_number"],
}
for chunk in pdf_chunks
]
# 메타데이터 추출
metadata_set_CSV = [
{
"ID": row["ID"],
"공사종류(대분류)": row["공사종류(대분류)"],
"공사종류(중분류)": row["공사종류(중분류)"],
"공종(대분류)": row["공종(대분류)"],
"공종(중분류)": row["공종(중분류)"],
"사고객체(대분류)": row["사고객체(대분류)"],
"사고객체(중분류)": row["사고객체(중분류)"]
}
for _, row in train.iterrows()
]
# metadata_set_CSV를 DataFrame으로 변환
df_metadata = pd.DataFrame(metadata_set_CSV)
# NaN 값이 있는지 확인
nan_check = df_metadata.isna().any()
# 결과 출력
print("각 컬럼의 NaN 여부:\n", nan_check)
# NaN 값이 있는 행 추출
nan_rows = df_metadata[df_metadata.isna().any(axis=1)]
# NaN 값이 있는 행이 있다면 출력
if not nan_rows.empty:
print("NaN 값을 포함한 행:\n", nan_rows)
else:
print("NaN 값이 포함된 행이 없습니다.")
# Train
vectorstore = Chroma.from_texts(train_documents, embedding, metadatas=metadata_set_CSV)
# PDF
vectorstore2 = FAISS.from_texts(text_set, embedding, metadatas=metadata_set)
이제 임베딩까지 완료했으면, Vector DB로 데이터를 옮길 차례입니다. 저는 PDF와 CSV를 모두 사용하기 위해 두 가지 Vector DB를 활용하였고 여기서 사용된 것은 Chroma와 FAISS를 사용하였습니다. 이를 통해서 PDF와 CSV를 활용하여 각각의 벡터 저장소를 생성하였습니다. 이 과정에서 전에 생성한 메타 데이터들은 metadatas를 통해 별도로 추가하였습니다.
7. Retriever (Ensemble Retriever)
# Train
retriever = vectorstore.as_retriever(search_type="similarity", search_kwargs={"k": R_k})
# PDF
retriever2 = vectorstore2.as_retriever(search_type="similarity", search_kwargs={"k": R_k})
ensemble_retriever = EnsembleRetriever(
retrievers=[retriever, retriever2],
weights=Ensemble_rate,
)
# LLM 모델 로드 (4-bit 양자화)
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type='nf4',
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=torch.float16
)
model = AutoModelForCausalLM.from_pretrained(LLM_Model, quantization_config=bnb_config, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(LLM_Model)
text_generation_pipeline = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
do_sample=False, # 결정론적 생성
return_full_text=False,
max_new_tokens=Max_token_length,
device_map="auto"
)
# 경고를 비활성화할 수도 있습니다.
import warnings
warnings.filterwarnings("ignore", category=UserWarning, module='transformers')
이제 검색기(Retriever)의 차례입니다. 저는 Retriever 중에서 Ensemble 기법을 사용하였습니다. 따라서 제가 구성한 모델은 PDF와 CSV를 둘 다 참고하여 답을 작성하는 데 활용할 수 있고 이 과정에서 검색 결과의 개수는 3개로 설정하였습니다. 그리고 구축한 Ensemble Retriever는 weights=Ensemble_rate를 통해 결과의 가중치를 부여하여 최종 검색 결과를 조합하게 됩니다. 예를 들어, Ensemble_rate = [0.5, 0.5]가 되면 전에 생성한 벡터 저장소에서 참고를 반반씩 한다는 것이고 해당 비중에 따라서 최종 검색 결과의 조합이 달라집니다.
그리고 이후에는 LLM 모델을 위해서 양자화 설정을 정의합니다. 이 과정에서 모델의 메모리 사용량을 줄이고 속도를 높이기 위한 양자화가 진행됩니다. 그리고 사전 훈련된 언어 모델을 불러오고 해당 모델은 허깅페이스로부터 CarrotAI/Llama-3.2-Rabbit-Ko-3B-Instruct-2412 모델을 사용하였습니다. 원래 LG사의 모델을 사용하려고 했으나, 대회 규정에 어긋나는 모델이기 때문에 저는 이 모델을 사용했습니다. 물론 다른 모델들도 많지만, 추론을 하는 데 너무 많은 시간이 소요되고 제가 원하는 결과를 출력하지 못했기 때문에 저는 해당 모델 사용을 결정하였습니다.
8. Prompt Design
prompt_template = """
Your mission is to be a safety expert answer bot. When given the {question}, you must provide an answer **only** if the question is related to **construction, safety, or safety measures**.
If the question is **NOT** related to **construction, construction safety tasks, or construction safety plan tasks**, respond with:
### 답변 : "업무와 관련이 없는 질문입니다."
### 끝.
Your answer **MUST** be in **only one sentence.
Your answer **MUST** be written **only in Korean**.
If any of the above instructions are violated, a penalty will be applied.
Make sure to strictly follow these rules.
### 질문:
{question}
"""
llm = HuggingFacePipeline(pipeline=text_generation_pipeline)
# 커스텀 프롬프트 생성
prompt = PromptTemplate(
input_variables=["question"],
template=prompt_template,
)
어떻게 보면 제가 가장 고민했던 부분이 프롬프트 쪽인 것 같습니다. 저 같은 경우에는 답변을 생성할 때, 과연 TEST 데이터의 답변 대로 사람이 질문을 할까? 라는 의문에서 시작해서 여러 질문에 대답하는 모델을 원했기 때문에 1. PDF 내용을 기반으로 한 질문에는 어떻게 대답을 할까? 2. 그 외의 질문이 들어오면 어떻게 반응할까? 라는 문제를 해결하기 위해 프롬프트를 구상한 결과 위와 같은 프롬프트 디자인을 구성해보았습니다. 저렇게 구성을 해도, 모델이 답변을 생성할 때 정말로 다양한 형식으로 답변을 하기 때문에 이는 추후에 나온 답변을 참고하여 답변 또한 추가로 전처리를 해야만 했습니다.
한국어로 답변을 하면 영어로 답변하고, 형식에 맞춰서 하라 그러면 이상하게 답변하고 이 것이 모델 마다 다 다른 특징을 보이니, 정말 이 과정이 가장 오래 걸리고 스트레스도 많이 받은 것 같습니다. 이 과정을 겪으니, 프롬프트 디자인은 별도로 공부해야겠다는 생각이 들었습니다.
9. Reference Check
import random
Sample_num = 5
# combined_training_data에서 랜덤하게 5개 샘플 선택
sample_questions = random.sample(list(combined_training_data['question']), Sample_num)
# 각 샘플에 대해 compression_retriever에서 검색된 문서 확인
for idx, question in enumerate(sample_questions):
print(f"샘플 {idx+1}: {question}\n")
# 검색 수행
retrieved_docs = ensemble_retriever.get_relevant_documents(question)
print("검색된 문서들:")
for doc_idx, doc in enumerate(retrieved_docs):
print(f"Document {doc_idx+1}: {doc.page_content}")
print(f"Meta Data : {doc.metadata}\n") # 메타데이터 출력
print("=" * 100) # 가독성을 위한 구분선
이제 Chain을 구성하기 전에 Retriever가 정말로 PDF와 CSV를 잘 참고하는 지 확인하기 위한 Reference Check 과정을 수행하였습니다. 일단 결과를 보아하니, CSV와 PDF를 적절히 잘 참고하는 것 같습니다.
10. RAG Chain
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
chain = (
{"context": ensemble_retriever|format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
다음으로는 RAG Chain을 구성하였습니다. 여기서는 이제 Retriever + LLM + Prompt가 합쳐져서 질문에 대한 답을 검색하고 이에 대한 프롬프트 디자인을 통해 적절한 답변을 생성하기 위한 모든 과정을 합치는 과정입니다. 해당 체인을 구성하면 아래와 11번과 같은 구성을 확인할 수 있습니다.
11. Visulaization in Langchain
chain.get_graph().print_ascii()
12. Sample Test
# 테스트 데이터 통합 생성
combined_test_data = test.apply(
lambda row: {
"question": (
f"긴급상황입니다. 작업 프로세스는 '{row['작업프로세스']}'이며, 인적사고는 '{row['인적사고']}' 그리고 사고 원인은 '{row['사고원인']}'입니다. "
f"재발 방지 대책 및 향후 조치 계획은 무엇인가요?"
)
},
axis=1
)
# DataFrame으로 변환
combined_test_data = pd.DataFrame(list(combined_test_data))
# 테스트 실행 후 결과 저장
test_results_t = []
metadata_list_t = [] # 메타데이터를 저장할 리스트
preview_count = 10
# 미리 보기 샘플 수
preview_data = combined_test_data.sample(n=preview_count)
print("테스트 실행 시작... 총 테스트 샘플 수:", preview_count)
# tqdm을 사용하여 진행 상황 표시
for idx, row in tqdm(preview_data.iterrows(), total=len(preview_data), desc="테스트 진행 중", unit="샘플"):
# RAG 체인 호출 및 결과 생성
prevention_result = chain.invoke(row['question'])
if isinstance(prevention_result, str):
result_text = prevention_result # 문자열이라면 그 자체를 사용
else:
result_text = prevention_result.get('result', '')
# 질문과 결과를 함께 저장
test_results_t.append({"question": row['question'], "result": result_text})
# 가장 높은 순위의 문서 메타데이터 수집
retrieved_docs = ensemble_retriever.get_relevant_documents(row['question'])
if retrieved_docs:
top_doc = retrieved_docs[0] # 가장 높은 순위의 문서
if "source" in top_doc.metadata: # PDF 문서일 경우
metadata_list_t.append({
"Type": 'pdf',
"ID": None,
"Title": top_doc.metadata["source"],
"Page_number": top_doc.metadata["page_number"]
})
elif "ID" in top_doc.metadata: # CSV 문서일 경우
metadata_list_t.append({
"Type": 'csv',
"ID": top_doc.metadata["ID"],
"Title": None,
"Page_number": None
})
print("\n테스트 실행 완료! 총 결과 수:", len(test_results_t))# 데이터프레임 생성
metadata_test = pd.DataFrame(metadata_list_t)
metadata_test
# 각 질문에 대해 검색된 문서 및 답변 출력
for idx, result in enumerate(test_results_t):
question = result["question"]
answer = result["result"] # 답변 가져오기
print(f"질문 {idx + 1}: {question}\n")
print(f"답변 {idx + 1}: {answer}\n") # 답변 출력
# 검색 수행
retrieved_docs = ensemble_retriever.get_relevant_documents(question)
print("검색된 문서들:")
for doc_idx, doc in enumerate(retrieved_docs):
print(f"Document {doc_idx + 1}: {doc.page_content}")
print(f"Meta Data: {doc.metadata}\n") # 메타데이터 출력
print("=" * 100) # 가독성을 위한 구분선
13. PDF Based Question
# 질문 리스트
questions = [
"크레인 운전원이 지켜야할 안전 수칙에 대해 말하시오.",
"곤돌라 작업대가 허용 하강 속도를 초과하면 어떤 조치를 취해야 하는가?",
"암반 변화 구간의 발파 작업에는 무엇을 해야 하는가?",
"부재의 현장 반입 시 해야되는 작업에 대해서 말하시오.",
"단위공종별 작업 시작 전 해야되는 일들에 대해 설명하시오.",
"시스템 동바리 조립시 작업자가 해야되는 업무에 대해 설명하시오.",
"U자 걸이로 사용해야되는 안전대 '호' 번호는?",
"야간 근로자의 작업 시간에 따른 휴식 시간은?",
"내장 공사에서 작업 발판 사용시 폭의 기준은?",
"캐트워크가 바람에 흔들리는 경우에 해야되는 조치는?"
]
# DataFrame 생성
PDF_question = pd.DataFrame({'question': questions})
# 테스트 실행 후 결과 저장
PDF_question['Result'] = '' # 결과 저장 컬럼 추가
PDF_question['Type'] = '' # 문서 유형
PDF_question['Doc_ID'] = None # 문서 ID (CSV)
PDF_question['Title'] = '' # 문서 제목 (PDF)
PDF_question['Page_number'] = None # 페이지 번호 (PDF)
# tqdm을 사용하여 진행 상황 표시
for idx, row in tqdm(PDF_question.iterrows(), total=len(PDF_question), desc="테스트 진행 중", unit="샘플"):
# RAG 체인 호출 및 결과 생성
prevention_result = chain.invoke(row['question'])
if isinstance(prevention_result, str):
PDF_question.at[idx, 'Result'] = prevention_result # 문자열 결과 저장
else:
PDF_question.at[idx, 'Result'] = prevention_result.get('result', '')
# 가장 높은 순위의 문서 메타데이터 수집
retrieved_docs = ensemble_retriever.get_relevant_documents(row['question'])
if retrieved_docs:
top_doc = retrieved_docs[0] # 가장 높은 순위의 문서
metadata = top_doc.metadata
if "source" in metadata: # PDF 문서일 경우
PDF_question.at[idx, 'Type'] = 'pdf'
PDF_question.at[idx, 'Title'] = metadata["source"]
PDF_question.at[idx, 'Page_number'] = metadata.get("page_number", None)
elif "ID" in metadata: # CSV 문서일 경우
PDF_question.at[idx, 'Type'] = 'csv'
PDF_question.at[idx, 'Doc_ID'] = metadata["ID"]
print("\n테스트 실행 완료! 총 결과 수:", len(PDF_question))

14. Unrelated Question
import pandas as pd
from tqdm import tqdm
# 엉뚱한 질문 리스트
unrelated_questions = [
"하늘은 무슨 색인가요?",
"한국에서 가장 유명한 음식은 무엇인가요?",
"우주에서는 소리가 들릴까요?",
"고양이는 왜 박스를 좋아하나요?",
"로마 제국이 멸망한 이유는 무엇인가요?",
"인간의 평균 수면 시간은 몇 시간인가요?",
"이탈리아의 수도는?",
"한국에서 가장 높은 산은 어디인가요?",
]
# DataFrame 생성
Unrelated_questions = pd.DataFrame({'question': unrelated_questions})
# 테스트 실행 후 결과 저장
Unrelated_questions['Result'] = '' # 결과 저장 컬럼 추가
# tqdm을 사용하여 진행 상황 표시
for idx, row in tqdm(Unrelated_questions.iterrows(), total=len(Unrelated_questions), desc="테스트 진행 중", unit="샘플"):
# RAG 체인 호출 및 결과 생성
prevention_result = chain.invoke(row['question'])
# prevention_result에 "업무와 관련이 없는 내용입니다."가 있으면 그 문장을 그대로 사용
if isinstance(prevention_result, str):
if "업무와 관련이" in prevention_result:
Unrelated_questions.at[idx, 'Result'] = "업무와 관련이 없는 질문입니다." # 해당 문장으로 변경
else:
Unrelated_questions.at[idx, 'Result'] = prevention_result # 문자열 결과 저장
else:
result_text = prevention_result.get('result', '')
if "업무와 관련이" in result_text:
Unrelated_questions.at[idx, 'Result'] = "업무와 관련이 없는 질문입니다." # 해당 문장으로 변경
else:
Unrelated_questions.at[idx, 'Result'] = result_text # 결과 저장
# 가장 높은 순위의 문서 메타데이터 수집
retrieved_docs = ensemble_retriever.get_relevant_documents(row['question'])
if retrieved_docs:
top_doc = retrieved_docs[0] # 가장 높은 순위의 문서
print("\n테스트 실행 완료! 총 결과 수:", len(Unrelated_questions))
print(Unrelated_questions['Result'])
15. Inference & TEST
import re
from tqdm import tqdm
# 테스트 실행 및 결과 저장
test_results = []
metadata_list = []
print("테스트 실행 시작... 총 테스트 샘플 수:", len(combined_test_data))
# tqdm을 사용하여 진행 상황 표시
for idx, row in tqdm(combined_test_data.iterrows(), total=len(combined_test_data), desc="테스트 진행 중", unit="샘플"):
# RAG 체인 호출 및 결과 생성
prevention_result = chain.invoke(row['question'])
if isinstance(prevention_result, str):
result_text = prevention_result
else:
result_text = prevention_result.get('result', '')
# '답변' 이전 제거
first_sentence = re.sub(r'.*답변\s*[::]?\s*', '', result_text)
# '답변 :' 또는 '답변:' 제거
first_sentence = re.sub(r'답변\s*[::]?\s*', '', first_sentence)
# '.'와 ','을 제외한 특수문자 및 줄바꿈 문자 제거
first_sentence = re.sub(r'[^가-힣0-9\s.,]', '', first_sentence).replace('\n', '')
# 첫 번째 문장 끝나면 그 뒤의 내용 제거
first_sentence = re.split(r'[.!?]\s', first_sentence, maxsplit=1)[0].strip()
if "업무와 관련이" in first_sentence:
first_sentence = "업무와 관련이 없는 질문입니다."
# 결과 저장
test_results.append({
"question": row['question'],
"result": first_sentence
})
# 가장 높은 순위의 문서 메타데이터 수집
retrieved_docs = ensemble_retriever.get_relevant_documents(row['question'])
if retrieved_docs:
top_doc = retrieved_docs[0] # 가장 높은 순위의 문서
if "source" in top_doc.metadata: # PDF 문서일 경우
metadata_list.append({
"Type": 'pdf',
"ID": None,
"Title": top_doc.metadata.get("source"),
"Page_number": top_doc.metadata.get("page_number")
})
elif "ID" in top_doc.metadata: # CSV 문서일 경우
metadata_list.append({
"Type": 'csv',
"ID": top_doc.metadata.get("ID"),
"Title": None,
"Page_number": None
})
print("\n테스트 실행 완료! 총 결과 수:", len(test_results))
test_results[:10]
■ 마무리
여기까지 약 한 달 동안 수행했던 RAG 기반의 건설공사 사고 예방 및 대응책 생성 경진대회 코드였습니다. 여기까지 오는 것도 정말 많은 참고와 서적 등을 통해 구현했는 데, 다른 분들의 코드를 보니 전혀 알지 못했던 방식들이 많이 쏟아지는 것 같습니다. 나름 열심히 한 것 같지만, 정말로 세상에는 많은 전문가들이 있는 것 같습니다. 이에 위축되지 말고 다른 분들 것을 잘 배워서 더 열심히 해보자는 다짐을 해봅니다. 그래도 이번 기회를 통해서 RAG 도 구축해보고 LLM에 대한 경험치도 쌓았으니, 이제 기본 중의 기본인 NLP부터 차분하게 공부해봐야겠습니다. 대회에 참여하신 많은 분들 고생하셨습니다.

■ 진행 중 대회
악성 URL 분류 AI 경진 대회 :
https://dacon.io/competitions/official/236451/overview/description
악성 URL 분류 AI 경진대회 - DACON
분석시각화 대회 코드 공유 게시물은 내용 확인 후 좋아요(투표) 가능합니다.
dacon.io
채무 불이행 여부 예측 해커톤 :
https://dacon.io/competitions/official/236450/overview/description
채무 불이행 여부 예측 해커톤: 불이행의 징후를 찾아라! - DACON
분석시각화 대회 코드 공유 게시물은 내용 확인 후 좋아요(투표) 가능합니다.
dacon.io
'Personal Projects > Dacon' 카테고리의 다른 글
| [Dacon] 채무 불이행 여부 예측 해커톤 (2) - EDA (0) | 2025.03.31 |
|---|---|
| [Dacon] 채무 불이행 여부 예측 해커톤 (1) - 후기 (0) | 2025.03.31 |
| [Dacon] 건설공사 사고 예방 및 대응책 생성 경진대회 (1) - 후기 (0) | 2025.03.24 |
| [Dacon] 부동한 허위매물 분류 해커톤 (3) - 최종 코드 (0) | 2025.02.28 |
| [Dacon] 부동산 허위매물 분류 해커톤 (2) - EDA (0) | 2025.02.28 |



